Spark Operator ❤ Quarkus
This attempts to describe the migration path of Spark Operator from the conventional (hotspot) JVM to quarkus.io / GraalVM.
![]()
![]()
Why
Applications written in Java that run on JVM are often long running in nature, and optimized for the peek performance. JVM maintains the counters of the method invocations and has also other ways to figure out what the hot paths in the byte code are. Only then it triggers the JIT compiler that produces the platform specific assembly code. Also when starting the JVM there is a huge overhead, because it needs to load all the possible classes and metadata about them, during the class loading the static initializers have to be run, etc.
On the other hand the micro services are often containerized and run in platforms such as Kubernetes and in this environment there is a demand for them to start and respond to requests as quickly as possible. The abovementioned peek performance isn’t really the issue here, because the containers are being stopped and started much more often. In other words, there is frequently not enough time for the JIT compiler to kick in. Good example is a serverless platform where the worker containers are supposed to have a very fast start.
GraalVM provides, among other polyglot features, also the ahead of time compilation capabilities and something called native image. With native image you can provide your jar files as the input for the GraalVM compiler and on the output you will end up with just one binary that contains everything including the JVM. It has a modified version of JVM called Substrate VM and it also contains a memory snapshot that was calculated during the compilation. The compilation process actually runs all the static initializers to save some time during the actual start of the application. This benefit comes with little price, reflection calls are not as easy as in normal JVM environment, and also the static initializer should not contain any complex logic that should be done actually during the run time, because the run time and compile time may happen in significantly different moments.
As for the reflective calls, one has to tell GraalVM compiler in advance what classes and methods will be used for reflection and whitelist them using a JSON file that is then passed to the native image tool. Here, I see the big advantage of a quarkus.io that helps with the native image build. It can automatically figures out what classes should be marked that require the reflection or you can use the annotation to explicitly mention them if quarkus misses them.
UPDATE: The automatic detection of reflective calls is actually added to GraalVM’s native image itself (docs). However, it doesn’t work in all possible situations.
Another nice feature of quarkus is that it provides some Java EE specs that wouldn’t work otherwise with the native image, for instance the CDI implementation or JAX-RS for rest services. Last but not least, it provides a set of maven plugins and tools for rapid development of web apps.
Spark Operator is a cloud native application that needs to start fast and have the small memory and container image footprint, so it was quite a natural choice to use the GraalVM’s native image and quarkus.io. Here I will describe the migration of the Abstract Operator SDK from the plain Java to a version that was digestible for quarkus and native images.
Challenges
I had the github issue that addressed the native image opened for a very long time, but it was very cumbersome to actually make it working. I hit namely this obstacles:
-
Build – Running the native build wasn’t easy and there is myriad of parameters that can be fine tunned, check the “one-liner” command I was originally using (cmd). Ugly, right?
-
Reflection – Once the compilation finally succeeded, Jackson and other and reflective calls during the (de)serilalization were not working and the operator was failing in run time on
ClasssNotFoundExceptions. The abstract-operator library itself uses reflection for finding the implementations of theAbstractOperatorclass during run time and the issue here is that the library itself can’t know in advance its client so each possible client would need to create the JSON file with the allowed classes. Working with fabric8 Kubernetes client also wasn’t seamless at the beginning -
Static Initializers – Necessity to change the code a bit, for instance the static initializers shouldn’t do anything complex or even start a thread due to the AOT compilation and heap snapshoting.
-
CI – Download, unzip and add to path and run the native build with
graalvmisn’t hard, but it complicates the continuous integration process. Spark Operator uses Travis CI and it provides a limited machines for the free plan so doing all of this may complicate things further.
d kill `d ps -q` || true && mvn clean install && cp /home/jkremser/install/graalvm-ce-19.0.2/jre/lib/amd64/libsunec.so ./target/ && ~/install/graalvm-ce-19.0.2/bin/native-image --no-server -H:Name=micro -J-Xmx4G -J-Xms4G -H:+JNI -H:EnableURLProtocols=https --allow-incomplete-classpath -H:ReflectionConfigurationFiles=classes.json -H:ResourceConfigurationFiles=resources.json -H:+ReportExceptionStackTraces -H:+ReportUnsupportedElementsAtRuntime --static -H:Name=app -jar ./target/spark-operator-*.jar && mv ./spark-operator-*-SNAPSHOT target/ && docker build -f Dockerfile.centos . -t foo && oc cluster up && oc login -u system:admin ; oc project default && sleep 2 && oc apply -f manifest/operator.yaml && sleep 8 && opLogs
Solutions/Workarounds
What quarkus.io promises is this simple diagram, so let’s look whether it was that easy.
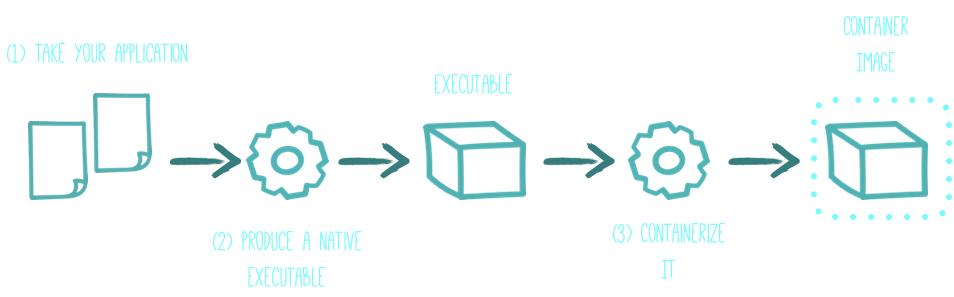
Quarkus diagram
Building the Native Image
Quarkus addresses the native build itself with a maven plugin that runs the command. For the spark operator and the abstract operator library we use the maven profile that calls this plugin. The profile is defined here.
So all it now takes is to call the:
mvn package -DskipTests -Pnative
Reflection
The majority of the reflective calls worked out of the box, futhermore, quarkus.io allows to use a sub set of CDI. So I could have replaced the library that was using the reflection for finding the classes that extended a class or had a annotation on them with CDI’s @Instance, check the code example:
class SDKEntrypoint.java:
@Inject @Any
private Instance<AbstractOperator<? extends EntityInfo>> operators;
...
// later in the code
List<AbstractOperator<? extends EntityInfo>> operatorList = operators.stream().collect(Collectors.toList());
if (operatorList.isEmpty()) {
log.warn("No suitable operators were found, make sure your class extends AbstractOperator and have @Singleton on it.");
}
So one little drawback here is that the concrete implementation of the operator now has to be an injectable entity, so @Singleton is a good candidate for that class. This unfortunately breaks the backward compatibility with the previous implementation.
The Abstract Operator Java SDK uses the JSON schema as the single source of truth for the shape of all the Custom Resources (CR) that operator manages and also automatically register itself as the OpenAPIv3 schema so that Kubernetes may check the actual schema validation. In other words, the framework itself registers the Custom Resource Definition (CRD) based on these JSON schemas + makes sure the schema validation will work with K8s.
What it also does is generating Java POJOs from these JSON schemas, so that user of the SDK may extract the right information from the custom resource in the code and react correctly on it. However, these generated classes weren’t automatically detected by quarkus.io for the reflective calls, so the operator failed in run time when deserializing the CRs. Luckily, the jsonschema2pojo library can change the behavir of the class generation by providing its own “Annotator” Using that fact, I’ve created a annotator that puts the @RegisterForReflection on each generated class and quarkus can find the classes and register them without any issues.
The annotator (source):
package io.radanalytics.operator.annotator;
import com.fasterxml.jackson.databind.JsonNode;
import com.sun.codemodel.JDefinedClass;
import org.jsonschema2pojo.AbstractAnnotator;
import io.quarkus.runtime.annotations.RegisterForReflection;
public class RegisterForReflectionAnnotator extends AbstractAnnotator {
@Override
public void propertyOrder(JDefinedClass clazz, JsonNode propertiesNode) {
super.propertyOrder(clazz, propertiesNode);
clazz.annotate(RegisterForReflection.class);
}
}
The kubernetes client itself had some issues when running in the native image context,luckily they were aware of the fact that they need to run on native image and there is also an extension for the client that makes things working out of the box.
Static Initializers
This actually wasn’t big deal. The older version of GraalVM were quite aggressive with the optimization and were complaining also about static methods that didn’t take any params. My theory is that it tried to calculate their output and speculate on the fact that they will be returning the same answer all the time (no side effects). Old implementation of the Java Operator SDK was using the the static main method that naturally led user to use as many of the static code (methods, fields) as possible.
The CDI, however, allows to use:
void onStart(@Observes StartupEvent event) // ~ main method
void onStop(@Observes ShutdownEvent event) // ~ shutdown hook
@PostConstruct
void init(){ // for preparing the ground
Continuous Integration
This is actually still to be done.
Result
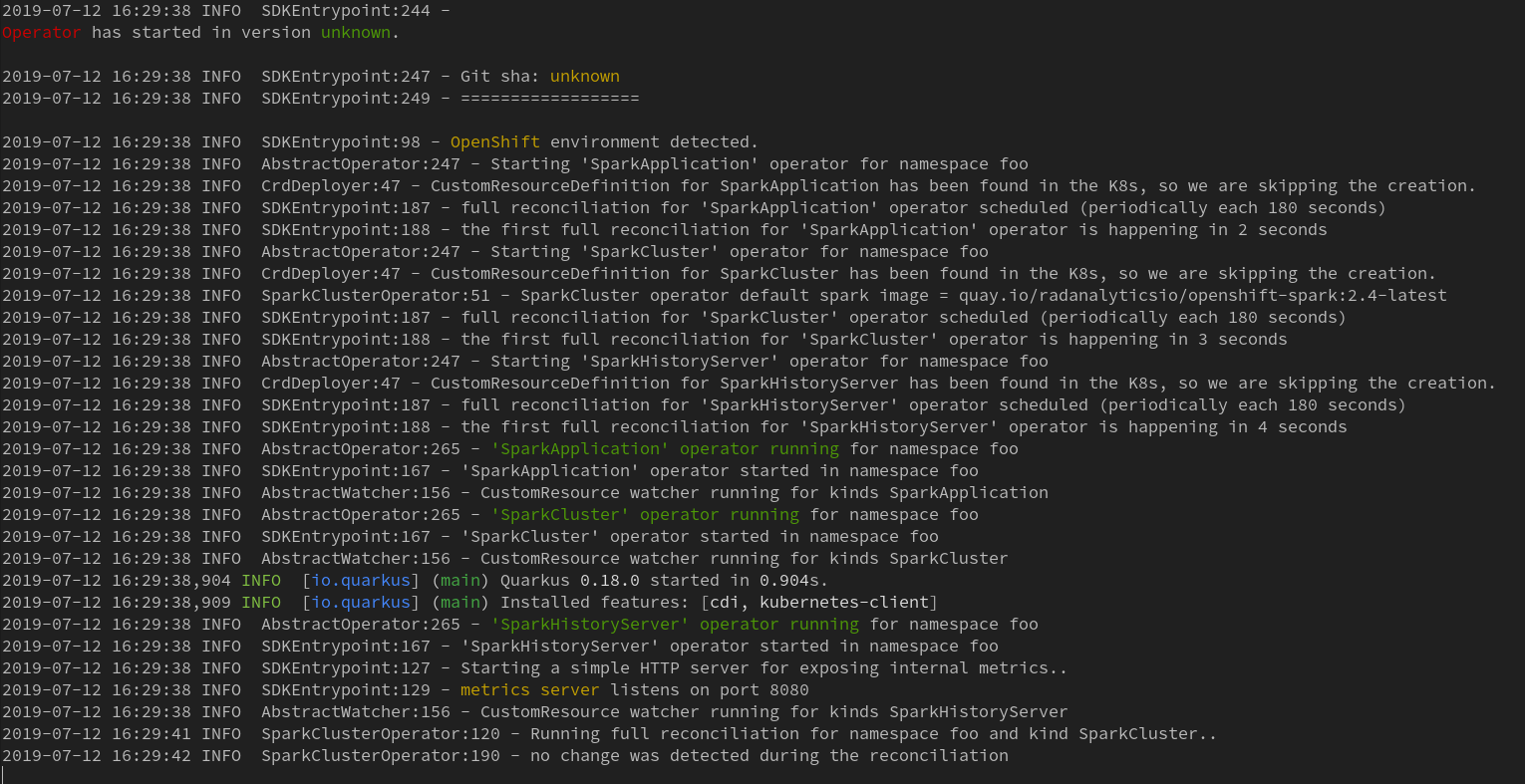
The startup time is below one second:
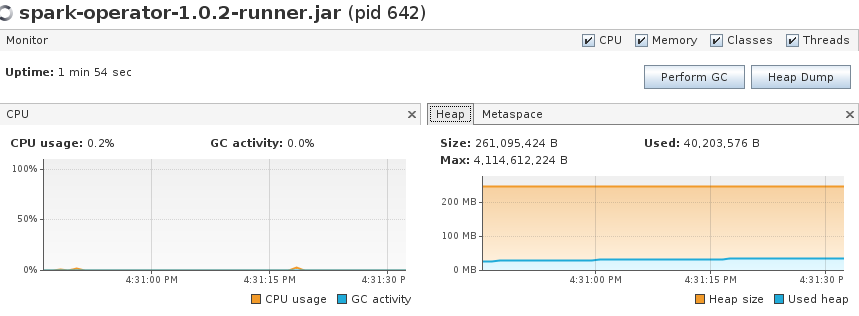
The memory footprint after startup is around 40 MB:
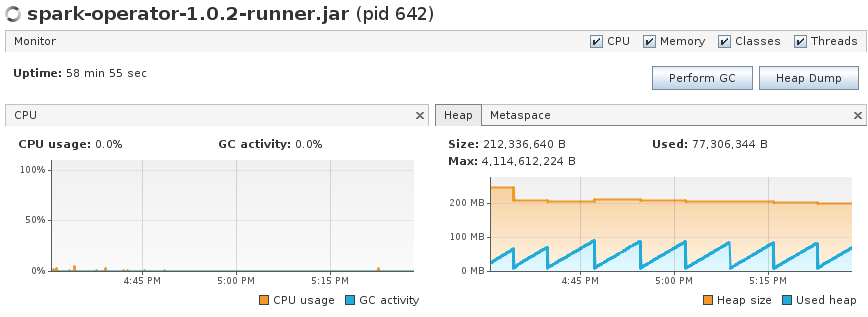
When running the application for a long run, it triggers the garbage collection around ~80 MB and the average is still around ~50 megs of memory consumption on heap, not bad for Java :)
The resulting container image is 102.3 MB for UBI as the base image and 69.4 MB for images based on Alpine.
images: https://quay.io/repository/radanalyticsio/spark-operator?tab=tags
Conclusion
What we have sacrificed here with using the AOT compilation is the best possible peak performance, in other words the optimized assembly code directly tailored for the profile of our long running app, however the benefits clearly overweight this issue. Operators aren’t supposed to do difficult parallel calculation, on the other hand they should start quickly, be small, reliable and have small memory footprint. And that we have achieved.
Links
- Spark Operator – radanalyticsio/spark-operator
- Abstract Operator – jvm-operators/abstract-operator
- GraalVM – oracle/graal
- Quarkus – quarkusio/quarkus
- Kubernetes Client – fabric8io/kubernetes-client
- kubernetes-client Quarkus Extension – repo
- jsonschema2pojo – joelittlejohn/jsonschema2pojo