Motivation
Cluster API (CAPI) provides a uniform workflow for deploying and operating Kubernetes clusters. It aims to abstract its user from the infrastructure level. The infrastructure in the form of VMs can be provided by a cloud provider like AWS or Azure. However, these platforms often support also managed Kubernetes experience (EKS, AKS), where a lot of features like load balancing or managed control planes are just there.
In this blog post we will be looking into a situation where no advanced features are provided and all we have is a virtualization platform like vSphere.
In this case, we are on our own and we need to manage the load balancing and IP management on our own. The article is tackling only the IPv4, but it could be generalized also to the IPv6 stack.
Problem Landscape
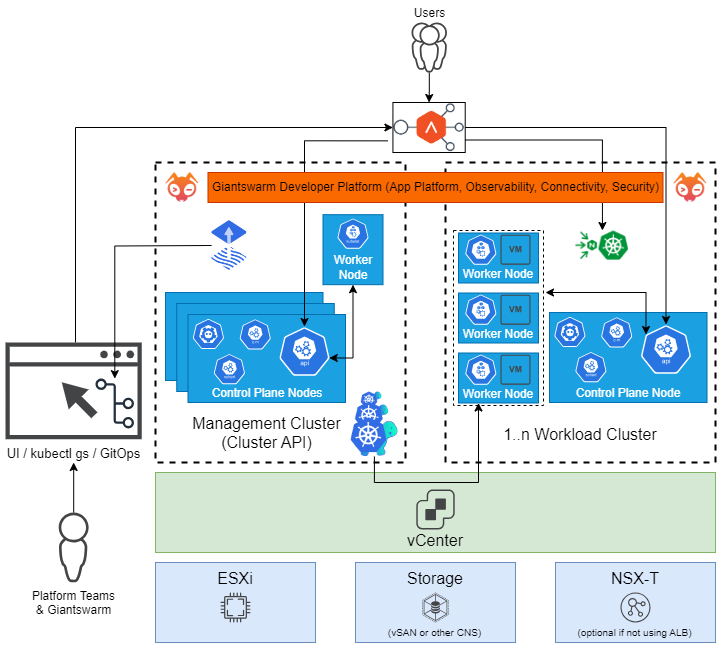
For the Cluster API to be a useful tool, it needs to be installed in certain flavor denoting what infrastructures it can talk to. This is captured in the infrastructure provider component. We will be using CAPV (Cluster API provider for vSphere). CAPV itself can already deploy a brand new Kubernetes cluster and also provide day-2 operations for it. This is done by dedicating one Kubernetes cluster as a management cluster (MC) where all these CAPI-related controllers run. Then when a set of resources (where the main/root one is the Cluster CR) is created, they start to do their thing and provision the (workload) cluster (WC).
Each infrastructure provider is different and provides a different level of comfort. For instance, the vSphere can create machines with given IPs or use DHCP. However, their CPI (cloud provider interface) component doesn’t support the load balancer for services so we need to use something else.
Also when creating a new cluster, at least the IP for the control plane needs to be known in advance (CAPV). The reason for this is that CAPV uses kube-vip by default to enable the control planes to run in HA (high availability) mode. Kubevip then selects one of the control planes as the primary one and creates a virtual IP for it. The failover is then solved by leader election mechanism by using Kubernetes primitives. When we create a new WC, we need a new free IP for it.
That’s the problem that can be solved by IP address management (IPAM).
Architecture
For better visualization of the problem, check the following diagram of our overall platform. The important part is the dedicated management cluster (MC) and CAPI controllers (the turtles) that can talk to vSphere and can create 1 to n Workload clusters (WCs), the rest is off-topic.
Part 1 - Service Load Balancer
As we mentioned before, we don’t have the full support from the cloud provider here so if we create a service with type LoadBalancer, it will stay in the pending state forever. Luckily, there are multiple solutions out there.
We have considered using MetalLB and Cilium but both of them required configuring BGP properly (ASN numbers, etc.) so for the sake of simplicity we choose to use a simple kube-vip project with ARP advertisement. That means that we currently deploy kube-vip in two different flavors:
a) used for control-plane HA (static pod on each control plane node)
b) used as a service LB (deployed as DaemonSet)
Part of the LB solution is also a kube-vip’s controller controller manager. This component is also specific to on-prem and its goal is to assign a new free IP from a given CIDR. It watches for all changes to a Service resource of type LoadBalancer and if the IP is not set, it assigns a new one. Then it is up to kube-vip LB to create a new virtual interface on the given node and advertise this new IP in the network using the layer 2 ARP protocol.
The range of IPs for service LB is defined as a ConfigMap:
λ k get cm kubevip -n kube-system -o jsonpath={.data} | jq
{
"cidr-global": "10.10.222.244/30"
}
It also supports a per-namespace ranges, but we don’t use it.
If configured and deployed properly, it works like this:
# deploy an example app
λ helm upgrade -i frontend --set ui.message="I am example app" podinfo/podinfo --version 5.1.1
# the --type=LoadBalancer is important here, it will create a service with this type
λ k expose service frontend-podinfo --port=80 --target-port=9898 --type=LoadBalancer --name podinfo-external
λ k get svc podinfo-external
podinfo-external LoadBalancer 172.31.119.240 <pending> 80:32062/TCP 1s
λ k get svc podinfo-external
podinfo-external LoadBalancer 172.31.119.240 10.10.222.244 80:32062/TCP 5s
λ curl -s 10.10.222.244 | grep message
"message": "I am example app",
\o/
Part 2 - IPAM for Workload Clusters (api server)
This is an orthogonal problem to the previous one, but it also includes IPAM. When creating a new cluster using Cluster API, one has to create a whole bunch of Kubernetes resources. There are tutorials, docs and presentations about CAPI, so we are not going to describe it in detail, but rather from a high perspective. These resources form a tree and are cross-linked by references in their .specs. CAPI consist of four controllers and each of them reacts on various CRs from that tree of yamls. Luckily the overall reconciliation of a new cluster can be paused by setting such a flag on the top-lvl CR - Cluster. We will use that later on.
What we are going to need is a controller/operator that keeps track of used IP addresses and can allocate new ones, ideally in Kubernetes native way. CAPI itself introduces the following CRDs:
IPAddressIPAddressClaim
And the idea is that one can create an IPAddressClaim CR with a reference to a “pool” and someone should create a new IPAddress with the same name as the claim satisfying the IP address range definition from the pool. One implementor of this contract is the cluster-api-ipam-provider-in-cluster that we ended up using.
Example:
λ k get globalinclusterippools.ipam.cluster.x-k8s.io
NAME ADDRESSES TOTAL FREE USED
wc-cp-ips ["10.10.222.232-10.10.222.238"] 7 6 1
λ cat <<IP | kubectl apply -f -
apiVersion: ipam.cluster.x-k8s.io/v1alpha1
kind: IPAddressClaim
metadata:
name: give-me-an-ip
spec:
poolRef:
apiGroup: ipam.cluster.x-k8s.io
kind: GlobalInClusterIPPool
name: wc-cp-ips
IP
ipaddressclaim.ipam.cluster.x-k8s.io/give-me-an-ip created
λ k get ipaddress give-me-an-ip
NAME ADDRESS POOL NAME POOL KIND
give-me-an-ip 10.10.222.233 wc-cp-ips GlobalInClusterIPPool
λ k get globalinclusterippools.ipam.cluster.x-k8s.io
NAME ADDRESSES TOTAL FREE USED
wc-cp-ips ["10.10.222.232-10.10.222.238"] 7 5 2
CAPV itself has support for IPAM already included, but this is limited to creating the VMs and assigning them IPs.
k explain vspheremachine.spec.network.devices.addressesFromPools
...
DESCRIPTION:
AddressesFromPools is a list of IPAddressPools that should be assigned to
IPAddressClaims. The machine's cloud-init metadata will be populated with
IPAddresses fulfilled by an IPAM provider.
TypedLocalObjectReference contains enough information to let you locate the
typed referenced object inside the same namespace.
It means that each VM created from a given template will have an IP address managed using the IPAddress and IPAddressClaim. That’s both overkill and also not sufficient. It’s overkill because we don’t need to take those non-important VMs (like worker nodes, or other control planes (CP) when running in HA) those precious IPs, we care only about one virtual API for all control planes running in HA mode as described in kube-vip (control plane HA use-case).
At the same time, it is not sufficient, because it can’t propagate that IP into other resources in that tree of CAPI objects where the information is needed:
Our Solution
So given we have installed the cluster-api-ipam-provider-in-cluster (CAIP - not to be confused with CAPI ;) we can now first create the IPAddressClaim, and only if it succeeds, only then use that IP in those places described above and create the set of resources for CAPI.
However, our resources for VsphereCluster are delivered as a Helm Chart so we can actually:
- deploy everything at once, all the CAPI resources, but also the
IPAddressClaim - create a pre-install job that will pause the
ClusterCR so that controllers will ignore it for a moment - create a post-install job in helm that will be waiting for the
IPAddressto exist - once the IP is obtained, it will propagate (
kubectl patch) the IP to those three abovementioned places - unpause the
ClusterCR
code: assign-ip-pre-install-job.yaml
All this jazz is happening in our implementation only if the cluster is created w/o any IP address in the .spec.controlPlaneEndpoint.host field. If the IP is specified, it will use the given/static one. The advantage of this approach is that IPAddressClaim is also part of the helm chart so if the helm chart got uninstalled, the claim is also deleted and the IP can be reused later on by another WC. Nice side-effect of this approach is that all the IPAM can be easily managed at one place in the MC using the CRDs.
\o/
Part 3 - Kyverno Policy
Another approach to IPAM for WCs problem would be using Kyverno and its ability to create validating and mutating webhooks much more easily. Originally, I wanted to introduce a mutating webhook that would intercept the creation of the Cluster resrource without any IP in it and assign this IP here.
The problem with this approach is that Kyverno’s internal language (JMESPath) is not powerful enough for this. It can’t expand CIDR ranges or keep track of how many IPs were taken, fill the holes, etc.
On the other hand, the validating webhook would be perfectly doable here with little help of helm-chart-fu again.
Kyverno can check for instance if certain field of a validated resource is contained in the set. So if we pre-populate the set with allowed values, the check itself is pretty easy:
...
validate:
deny:
conditions:
all:
- key: {{`"{{ request.object.spec.controlPlaneEndpoint.host }}"`}}
operator: NotIn
value: {{`"{{ allowedIps }}"`}}
...
allowedIps here are read from the ConfigMap:
...
context:
- name: wcAllowedIpsCm
configMap:
name: {{ .Release.Name }}-wc-allowed-ips
namespace: "{{ $.Release.Namespace }}"
- name: allowedIps
variable:
value: {{`"{{ wcAllowedIpsCm.data.\"allowed-ips\" | parse_yaml(@) }}"`}}
...
And finally, this configmap is pre-populated by a pre-install helm job with a little bit of good ol' bash in it: full code.
So if this Kyverno ClusterPolicy is active, it doesn’t allow anybody to create or change the .spec.controlPlaneEndpoint.host field of VsphereCluster (but it can work with any Infra cluster CR) to an IP that’s not coming from a given IP range.
In theory, Kyverno could also use the CAIP controller and introduce a Generate rule that would be creating those IpAddressClaims but that sounds like a lot of magic to me and those claims would stay there even if the cluster was uninstalled (the IP would not be freed).
Conclusion
In on-prem (or even bare metal) environments we are often on our own with CAPI and in this blog post, we have described our way to do-it-yourself IPAM solution. It provides a way to simply check available addresses using the kubectl. kube-vip is a very well-described open-source project and do its job as promised. We use it for
two different use cases (LB for services and HA for CPs).
And last but not least, Kyverno can guard what IPs are actually used in the Cluster resource and intercept disaster scenarios where one can assign an existing IP to a cluster. It will happilly provision the VMs, but then the api-server will be failing half of the requests because there are two VMs with the same static IP.
Implications
With this DIY solution, customer (platform developer) does not have to pay for more advanced solutions like NSX Advanced Load Balancer in case of vSphere ecosystem and at the same time, has the full control over the infrastructure. Nonetheless, with great power comes great responsibility 🕷
I think the following two images conclude nicely the IPAM in CAPI.
What users want to happen:
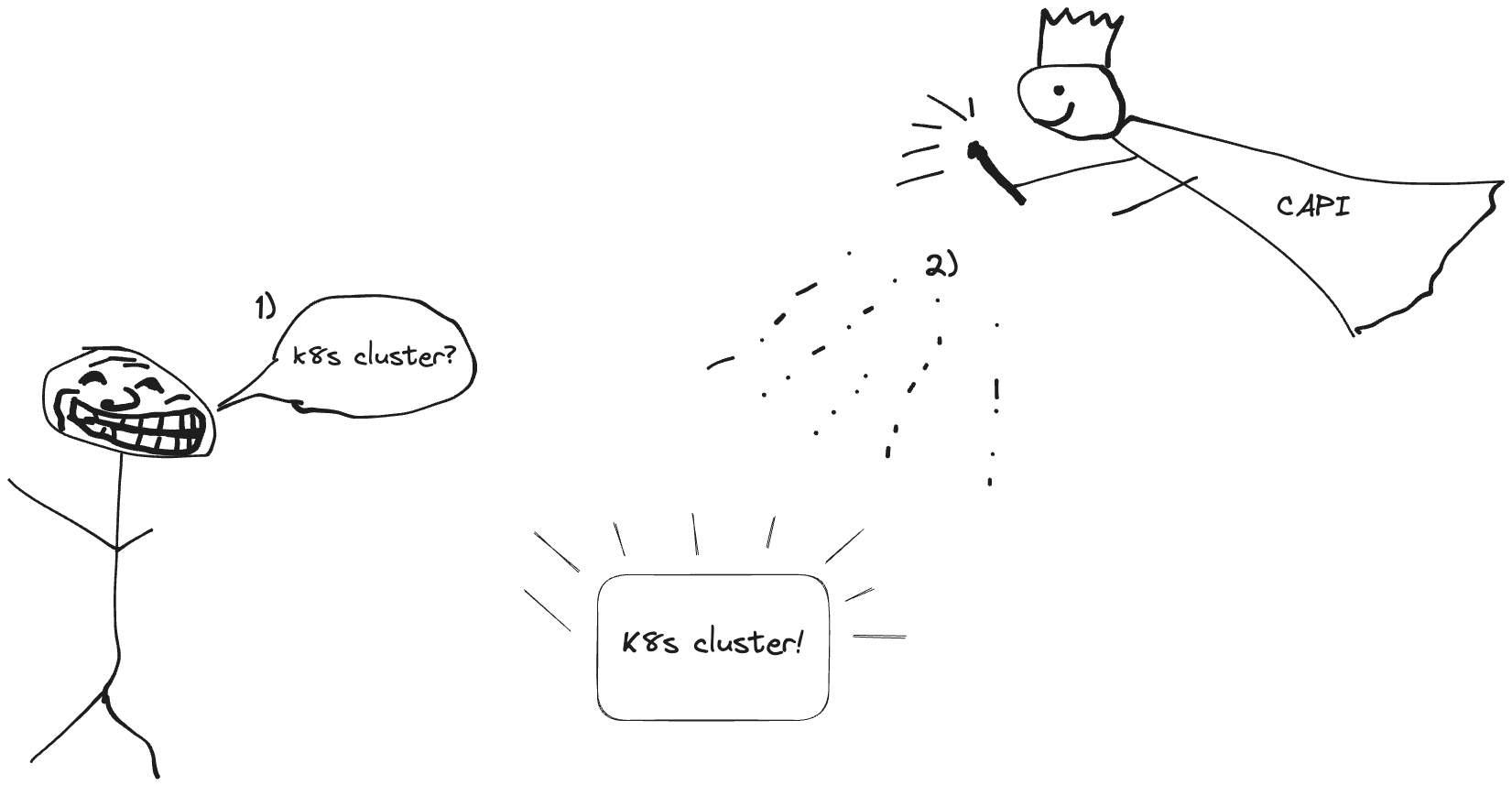
What actually happens:
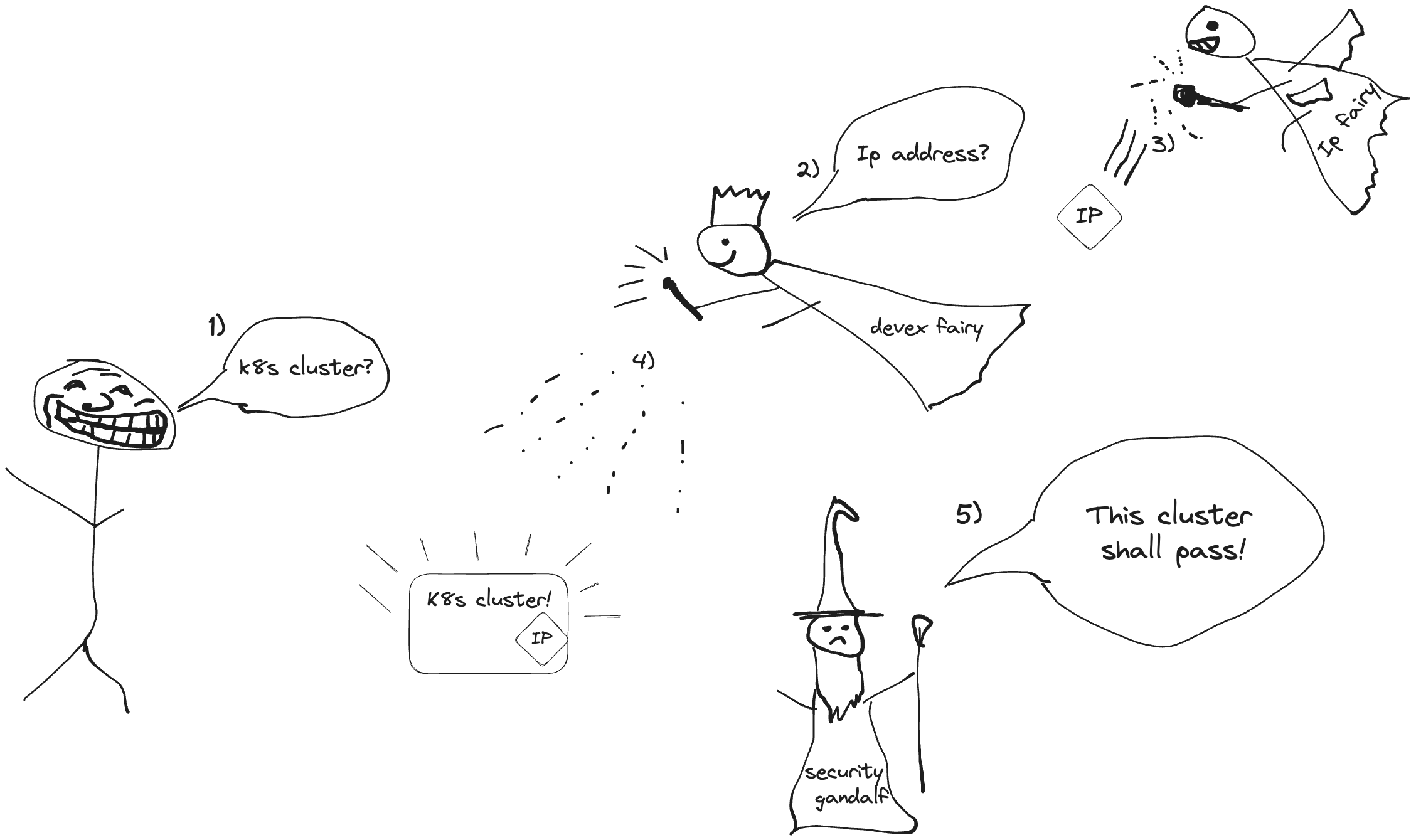
Where devex fairy is the CAIP & CAPI controllers and security gandalf is Kyverno.
Sources & Links
- [1]
Repo with the
VsphereClusterhelm chart – giantswarm/cluster-vsphere - [2] Repo with the IPAM controller – kubernetes-sigs/cluster-api-ipam-provider-in-cluster
- [3] Repo with the helm chart for IPAM controller (can also install the pool) – giantswarm/cluster-api-ipam-provider-in-cluster-app
- [4] Repo with the Kyverno policy – giantswarm/kyverno-policies-connectivity
- [5] kubevip project – kube-vip.io
- [6]
Repo with the
CAPVcontroller – kubernetes-sigs/cluster-api-provider-vsphere - [7]
Repo with the
CAPIcontroller – kubernetes-sigs/cluster-api